编辑推荐:
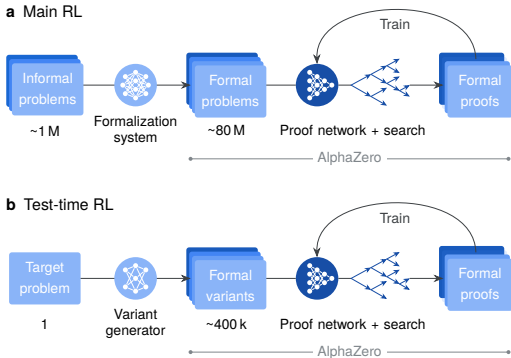
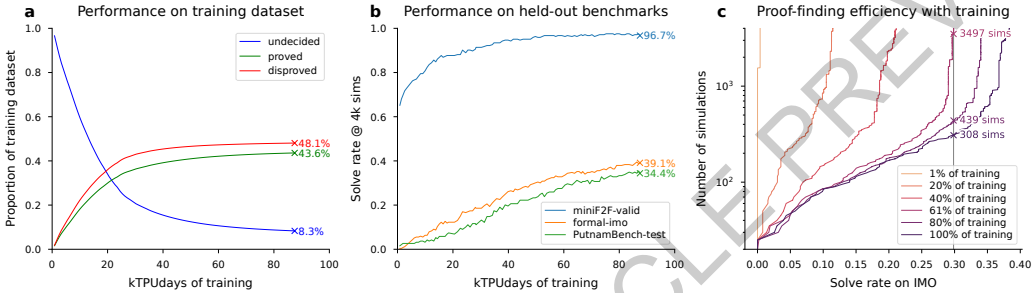
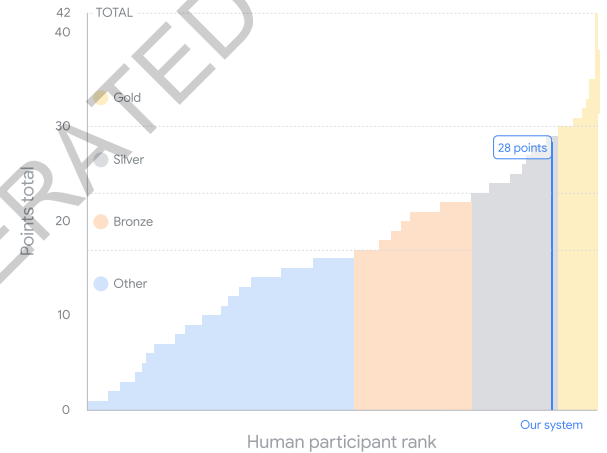
本刊推荐:为解决AI在复杂数学推理中缺乏形式化验证保证的问题,Google DeepMind团队开展了“AlphaProof:基于强化学习的形式数学推理”研究。该系统通过结合Lean定理证明器的严谨性与AlphaZero启发的强化学习框架,在包含数百万自动形式化问题的课程上训练,并引入测试时强化学习(TTRL)方法进行问题特定适应。研究结果显示,AlphaProof在miniF2F、formal-imo和PutnamBench等基准测试中创下新纪录,并在2024年国际数学奥林匹克竞赛(IMO)中解决了3道非几何问题,结合AlphaGeometry 2系统达到银牌水平,标志着AI在复杂数学推理领域的重大突破。
生物通 版权所有







