编辑推荐:
上述相关成果近日在《Genome Biology》(中文名《基因组生物学》)杂志上发表
【导读】
组蛋白修饰(histone modification)是表观遗传调控的重要层面,能够在不改变 DNA 序列的情况下影响染色质状态与基因表达。然而,在不同植物物种与组织条件下系统获取组蛋白修饰图谱通常依赖高成本实验,且数据分布不均衡,限制了大规模比较与功能注释。南京大学生命科学学院陈迪俊团队提出深度学习框架 SeiPlant,可基于 DNA 序列对组蛋白修饰进行预测,并在跨物种场景中展现出良好的泛化能力,为非模式植物的表观组推断与调控元件研究提供了新的计算工具。

研究背景 —— 表观遗传学的“数字孪生”挑战
在高等植物的生长发育和对环境变化的应答过程中,基因什么时候“打开”、在哪些组织里“打开”、打开到什么程度,往往决定了植物最终呈现出来的性状。决定这些开关的,不只有 DNA 序列本身。你可以把基因组想象成一本很长的说明书,而组蛋白修饰等表观遗传标记更像是贴在书页上的“便签”和“高亮”:它们不会改动文字内容,却能改变哪些段落更容易被翻到、哪些内容更容易被读到。通过影响 DNA 在细胞里如何折叠、哪些区域更“暴露”,这些标记会进一步影响调控蛋白能否顺利找到目标位置,从而影响基因表达,是连接“序列”和“性状”的关键一层调控。
问题在于,要想系统地画出这些“便签”分布图,传统上需要做实验(比如 ChIP-seq),这类实验对成本、周期、试剂质量(尤其是抗体)、以及能否获取足够的特定组织/细胞样本都很敏感。对于很多非模式植物和农业重要作物来说,样本难、数据少、重复性也更难保证,于是出现了一个现实的“数据断层”:我们在少数研究充分的物种里有比较完整的表观组数据,但在大量作物或野生植物中几乎没有。于是就引出了一个核心问题:能不能利用“已有物种”的数据训练一个可迁移的计算模型,让它在缺少实验数据的物种里,也能较可靠地推断这些组蛋白修饰等表观特征?
值得注意的是,尽管基于序列的调控特征预测已取得进展,但组蛋白修饰预测在跨物种场景中更具挑战性。与染色质开放性或特定转录因子结合位点相比,组蛋白修饰往往呈现更复杂的调控机制与更弱的直接序列决定性:其信号不仅受局部序列环境影响,还与细胞类型状态、转录活动、调控元件组合以及更大尺度的染色质背景相关。换言之,组蛋白修饰并不总是对应清晰、固定的“短序列模式”,而更可能由长程上下文与多因素协同产生,这使得传统基于局部 motif 的规则搜索难以奏效,也使跨物种泛化长期成为该领域的关键难题。
核心框架 —— SeiPlant 深度学习模型
在基因组调控建模中,序列到表观/调控表型往往表现为**多任务、多输出(multi-task / multi-target)**问题:同一段 DNA 序列可同时对应多种染色质相关信号(不同组蛋白修饰、不同组织/条件下的状态等),这些信号之间既共享部分序列决定因素,又具有各自的特异性。Sei 框架正是面向此类场景设计的通用深度学习建模范式:通过共享的序列表征学习与任务特异的输出层,将多个目标统一纳入同一模型中训练,从而在提升数据利用效率的同时,显式捕获不同调控信号之间的共性与差异。
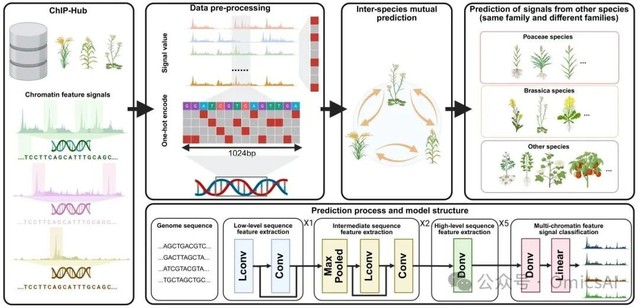
图1. SeiPlant整体框架
为什么在本研究中采用 Sei 框架
针对植物组蛋白修饰预测,尤其是跨物种推断的需求,本研究选择 Sei 框架主要基于三点考虑:
1. 适配多标记/多条件的预测需求:组蛋白修饰通常涉及多个标记(例如活性相关与抑制相关修饰),并在不同组织或处理条件下呈现显著差异。Sei 的多任务建模能够在统一框架内同时学习多个目标,避免为每个标记/条件重复训练独立模型。
2. 更强的泛化与迁移潜力:跨物种预测本质上要求模型学习相对“稳健”的序列决定因素,而非过拟合于单一物种的数据分布。Sei 通过共享特征抽取模块在多个目标上共同优化,有利于学习更具普适性的调控表征,从而提升跨物种场景下的可迁移性。
3. 能刻画组蛋白修饰的长程与弱特征依赖:与明确的短 motif 信号不同,组蛋白修饰往往受到更大尺度序列上下文与复合调控结构影响,需要模型具备长程依赖建模能力,并能对非编码区域的细微序列效应保持敏感。
SeiPlant 的关键建模特性
在结构上,SeiPlant 继承并面向植物基因组特性进行了适配,其核心模块强调两类能力:
1. 大感受野的上下文建模(dilated convolution):利用空洞卷积在不显著增加计算开销的前提下扩大感受野,使模型能够在 kb 级别整合序列上下文信息,从而更好地刻画与组蛋白修饰相关的长程依赖与复合序列语法。
2. 连续且细粒度的序列效应刻画(spline transformation):通过样条变换对序列相关特征进行更平滑、可表达的函数逼近,有助于捕捉非编码区中弱但一致的序列偏好信号,并提升模型对复杂序列背景的拟合能力。
精准预测:跨物种的“降维打击”
为系统评估 SeiPlant 在植物组蛋白修饰预测任务中的有效性与可迁移性,研究团队构建了覆盖多物种的验证流程,并从“同物种预测精度”“跨物种泛化规律”“类群级模型的适用性”“生物学解释”四个层面给出证据链。
1. 同物种预测:高精度重建组蛋白修饰信号
在水稻、拟南芥与玉米等物种上,SeiPlant 的预测性能保持在较高水平(AUROC 均超过 0.94)。模型生成的全基因组预测信号轨道与 ChIP-seq 实验轨道在整体形态与峰位分布上呈现高度一致性,表明该模型能够在序列层面有效捕获与组蛋白修饰相关的调控特征。
2. 跨物种预测:性能与系统发育距离呈相关趋势
跨物种迁移实验显示,模型的泛化性能与物种间系统发育距离密切相关:亲缘关系较近的物种之间迁移效果更好,而随着演化距离增加,预测性能逐步下降。例如,单子叶植物之间的迁移通常优于跨单子叶—双子叶的迁移。这一现象提示:不同植物类群在调控序列语法上存在可共享的“通用成分”,同时也包含一定程度的类群特异性调控背景。
3.类群级模型:在通用性与准确性之间实现更优折中
为提升对同一植物类群内多物种的适用性,团队进一步构建了禾本科(Poaceae)模型。结果表明,该模型在谷子、高粱、大麦等未参与训练的同科物种上仍保持优良表现,显示出面向类群的训练策略能够在“泛化能力”与“预测精度”之间实现更稳健的平衡,为表观组数据稀缺的大宗作物提供了可扩展的计算推断方案。
4.机制层面:序列顺式信息对组蛋白修饰模式具有关键贡献
通过进一步的模型分析,研究支持“局部 DNA 序列(顺式调控信息)对组蛋白修饰模式具有重要决定作用”的结论。这意味着,尽管组蛋白修饰受多层调控因素影响,但植物基因组序列本身已编码了可被模型学习的调控线索;在此基础上,SeiPlant 为解析植物调控序列语法、理解组蛋白修饰形成机制提供了新的计算视角。
工具落地:一键式植物表观信号“虚拟测序仪”
为促进方法的可复用与社区应用,团队同步提供了用户友好的自动化分析流程,使研究者能够在缺乏 ChIP-seq 条件的情况下快速获得可视化与可下游分析的组蛋白修饰预测结果。
输入简单:植物基因组 FASTA 文件(及必要的基础配置)。
输出丰富:全基因组尺度的组蛋白修饰预测信号轨道(BigWig 格式),可直接导入 IGV 或 UCSC Genome Browser 进行浏览与比较。
适用广泛:面向非模式植物与样本获取困难、实验成本较高的物种,为表观组参考图谱构建、候选调控区域筛选与功能注释提供低成本的计算替代方案。
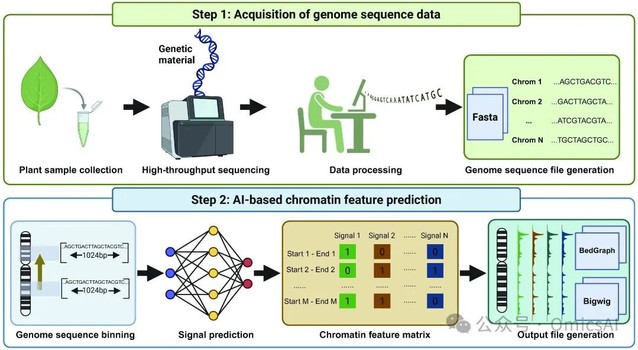
图2. SeiPlant的便捷化预测流程
总结与展望
SeiPlant 为植物组蛋白修饰的序列决定机制与跨物种可迁移性提供了系统证据,同时也为非模式植物与重要作物提供了可直接落地的计算推断工具。通过在缺乏 ChIP-seq 等实验条件的场景下生成可视化、可下游分析的表观信号轨道,SeiPlant 有望降低表观组研究的实验门槛,促进跨物种比较与功能注释。展望未来,将 SeiPlant 与环境胁迫条件下的多组学数据、组织/细胞类型分辨的表观数据以及三维基因组结构信息(如 Hi-C 相关特征)相结合,有望进一步提升对表观遗传调控动态与空间组织机制的解析能力,并服务于作物性状改良与适应性机制研究。
上述相关成果近日在《Genome Biology》(中文名《基因组生物学》)杂志上发表。
主要作者:南京大学博士研究生吕同轩为本文的第一作者,本科生韩荃(现为硕士一年级研究生)、李亦琳(大三)和梁晨(大三)也作为重要成员参与了本项工作。
通讯作者:南京大学生命科学学院陈迪俊为通讯作者。其团队长期致力于利用生物信息学与人工智能技术探索基因组调控的复杂机制,为功能基因组学研究提供前沿的计算方案。
特别致谢:浙江大学陈铭教授为本研究提供了重要指导与支持。
论文链接:https://doi.org/10.1186/s13059-025-03929-4
开源代码:https://github.com/compbioNJU/SeiPlant
生物通 版权所有





