随着电子健康记录(EHR)在基因组研究中日益普及,如何精准定义疾病表型成为关键挑战。目前大多数研究依赖国际疾病分类(ICD)代码进行病例-对照标注,但这种方法存在准确性有限、粒度粗糙、缺失模式非随机等问题。更棘手的是,特定疾病的病例数不足会降低统计效能并引入偏倚。ICD代码将疾病定义为离散实体,无法反映疾病风险的连续性特征。相比之下,对常见疾病进行更量化的表征可能更好地解决风险异质性,提升基于EHR表型的基因组研究效能。针对这一难题,哥伦比亚大学Cue Hyunkyu Lee等研究人员在《Nature Genetics》发表了题为"Liability threshold model-based disease risk prediction based on electronic health record phenotypes"的研究,提出了责任阈值表型整合(LTPI)方法。该方法创新性地结合遗传相关性与表型数据,包括诊断代码、家族疾病史、实验室测量值和生物标志物等二元和连续性状,为靶向疾病推导新的连续表型。LTPI方法的核心突破在于其自动性状选择算法(ATSA),该算法通过评估非靶向性状对靶向疾病的遗传贡献度(定义为非靶向性状解释的靶向疾病遗传方差比例),智能筛选最优性状组合。这种方法不仅提升了疾病风险预测性能,还能揭示与靶向疾病相关的非靶向性状特征。研究团队通过模拟研究和在eMERGE网络及英国生物样本库(UKBB)的实际应用,验证了LTPI的卓越性能。与传统的表型代码(PheCodes)、仅包含家族史的模型(LTFH)以及表型插补方法SoftImpute相比,LTPI在疾病风险预测和全基因组关联研究(GWAS)效能方面均表现出持续优势,同时保持了相似的假阳性率控制水平。关键技术方法包括:1)基于Geweke-Hajivassiliou-Keane(GHK)算法的后验平均遗传责任估计;2)利用连锁不平衡评分回归(LDSC)估计性状间遗传相关性;3)针对UKBB的404,981名英国白人参与者进行大规模表型整合分析;4)采用Regenie进行全基因组关联分析。
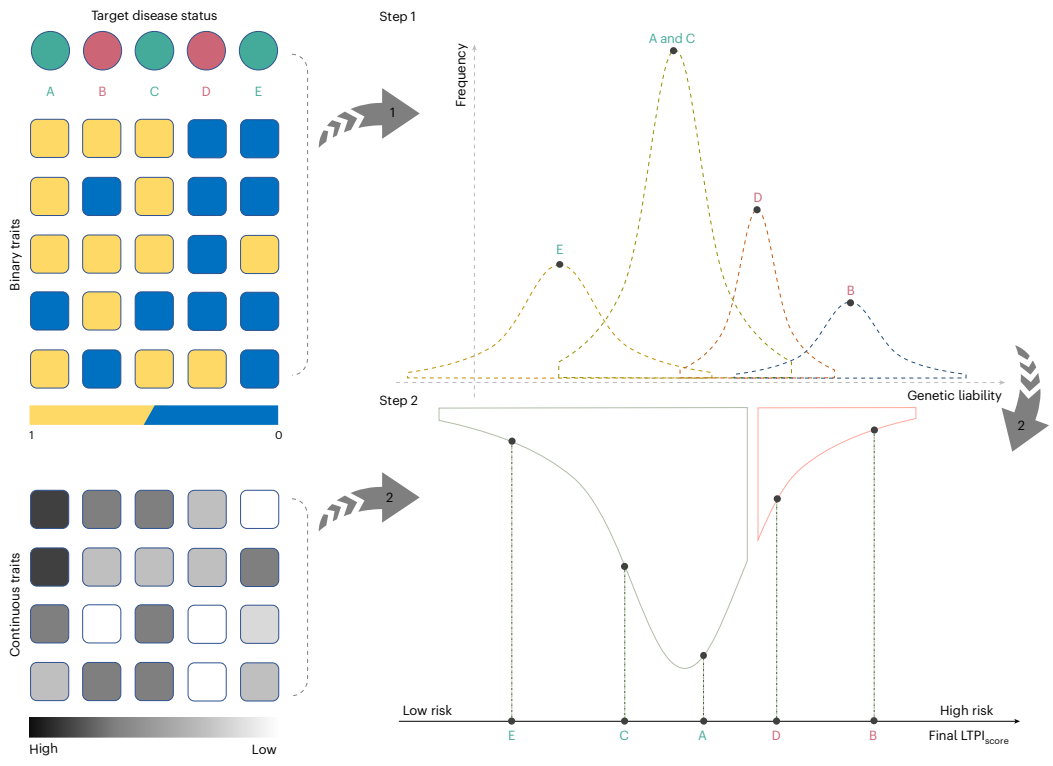
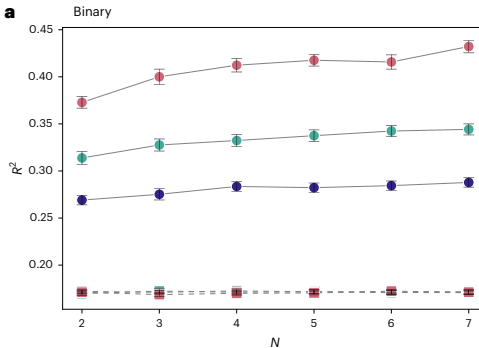
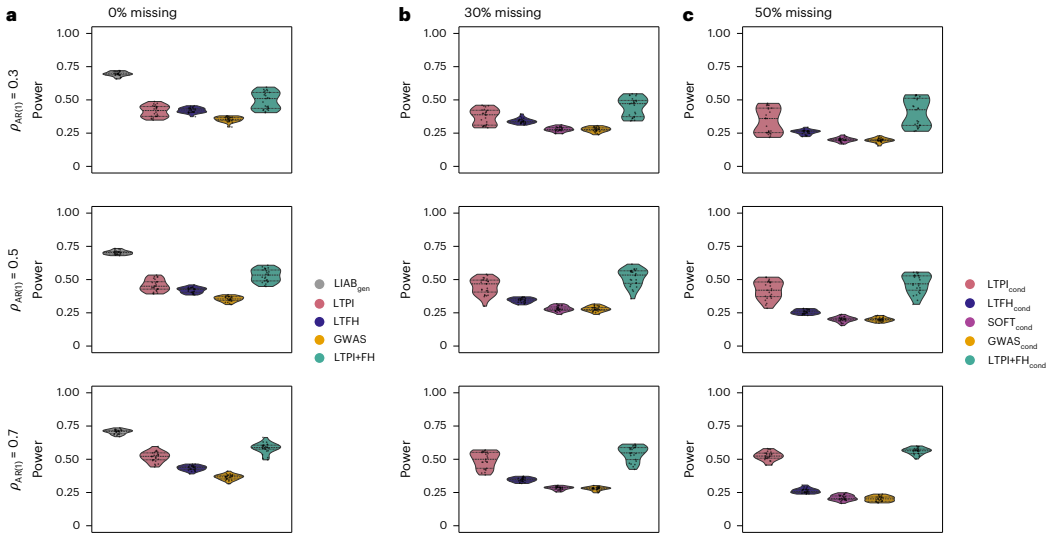
LTPI框架构建LTPI是基于责任阈值模型的靶向疾病预测框架,将未观察到的责任与非靶向PheCodes和连续表型相关联。如图1所示,该方法包含三个关键步骤:第一步计算靶向疾病的后验平均遗传责任(LTPIb),条件于二元非靶向性状;第二步利用额外的连续非靶向表型推导最大似然估计(LTPIc);第三步将LTPIb和LTPIc组合成最终LTPI评分。该方法的核心创新是ATSA,它基于评估非靶向性状对靶向疾病的遗传贡献度,自动选择最具信息量的性状组合。模拟验证性能通过包含300,000个个体的广泛模拟,研究人员验证了LTPI在疾病风险预测准确性(R2)、假阳性率(FPR)和GWAS效能方面的优势。结果显示,随着包含性状数量增加或遗传相关性(ρAR(1))提高,R2持续上升。当包含21个二元性状和5个连续性状时,平均R2LTPI达到0.62±0.005,较仅包含21个二元性状的模型提升42.53%。在遗传相关性(rg=0.7)和遗传率(h2=0.7)最高时,观察到最大R2为0.674。GWAS效能评估在无缺失数据情景下,当ρAR(1)=0.7时,LTPI较LTFH实现19.49%的效能提升(51.8±0.77% vs 43.35±0.38%)。结合LTPI和LTFH P值的Cauchy组合方法(LTPI+FH)进一步将效能提升至58.35±0.78%。在靶向表型30-50%缺失情景下,LTPIcond表现出强劲的稳健性,效能损失仅为2.21-17.59%,显著优于SoftImputecond和GWAScond。
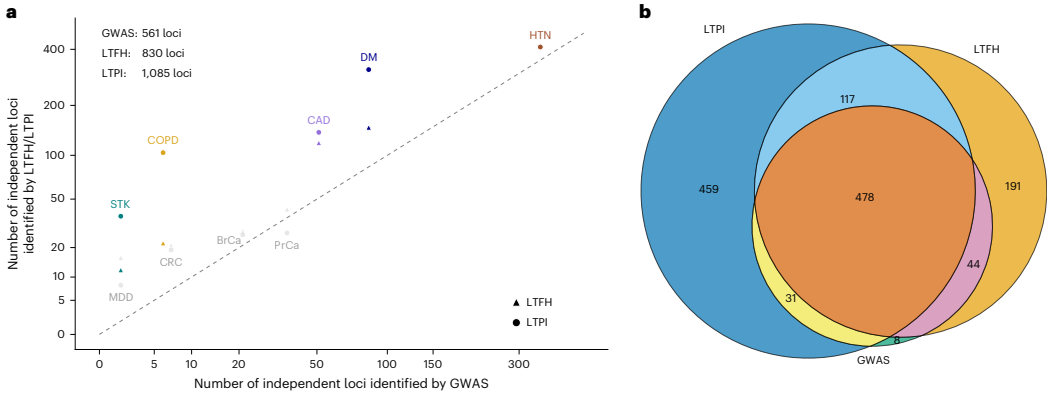
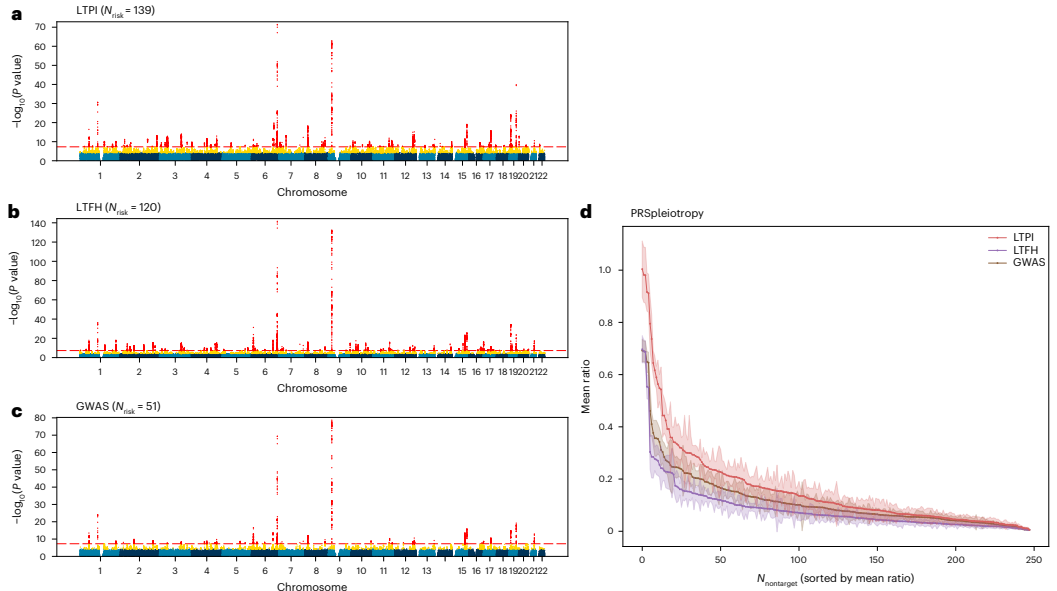
eMERGE网络应用在eMERGE-III数据集的42,823名欧洲个体中,研究人员以慢性肾脏病(CKD)为靶向疾病进行验证。通过手动选择和ATSA两种策略筛选非靶向性状,LTPI评分与基于肾小球滤过率分期的CKD表型呈现显著正相关(r=0.947;P<3.1×10-30)。对于G3期及以上CKD,LTPI versus G-stage的R2为0.325,优于PheCode的0.252。接收者操作特征曲线下面积(AUROC)达到0.798(G3及以上)和0.954(G4及以上)。UK生物样本库验证在404,981名英国白人参与者中,LTPI在9种疾病的风险预测中持续超越LTFH。GWAS分析显示,LTPI和LTFH分别恢复了标准GWAS发现位点的91%和93%,并识别出额外的独立关联。对于冠状动脉疾病(CAD),LTPI识别出139个风险位点,显著多于LTFH(120个)和GWAS(51个)。PRS多效性(PRSpleiotropy)分析表明,LTPI在利用多效信号增强效能的同时,保持了良好的特异性。