编辑推荐:
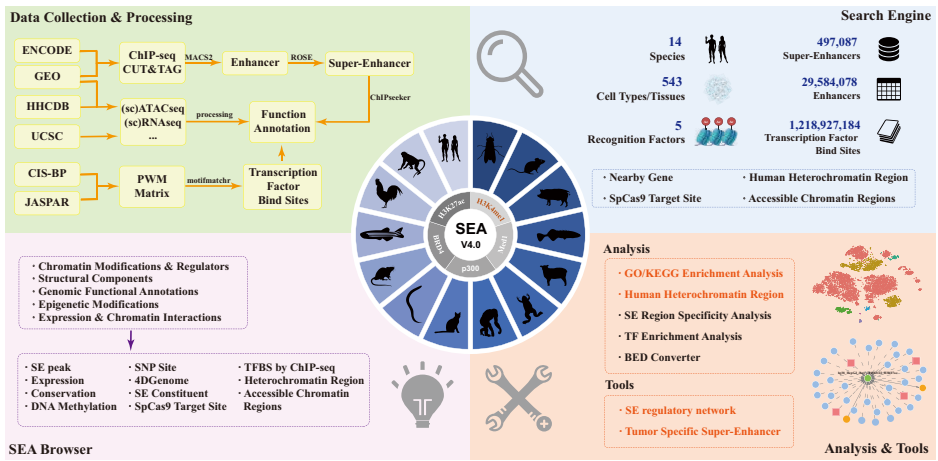
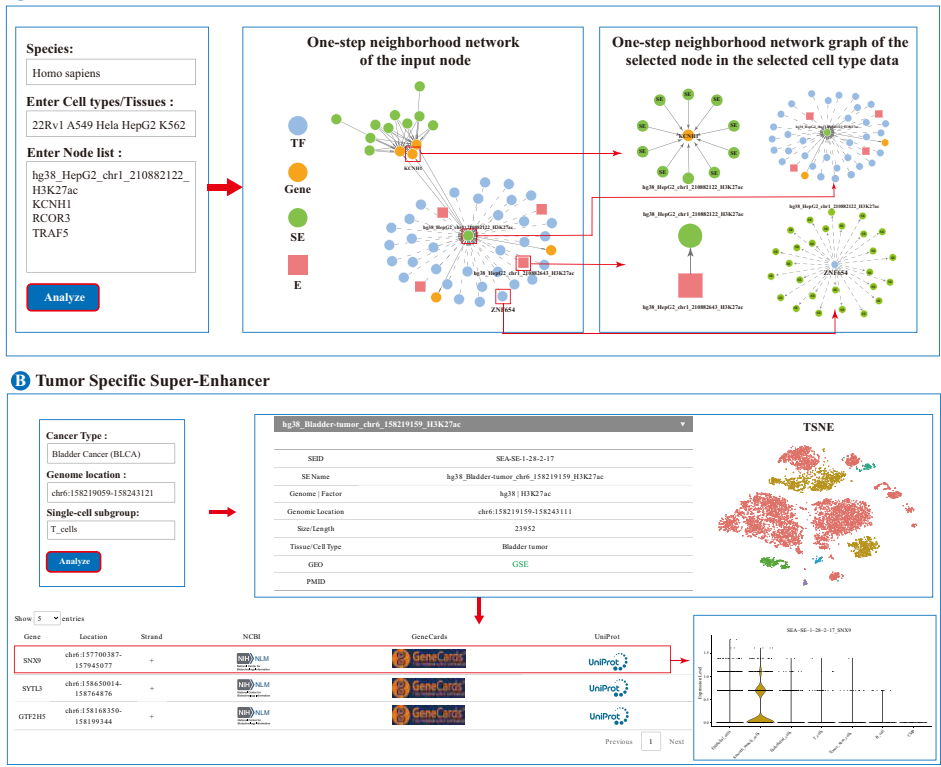
本研究针对超级增强子(SE)研究领域存在的数据分散、注释不全面、缺乏跨物种比较和肿瘤特异性分析工具等问题,开发了SEA version 4.0平台。研究人员整合了截至2024年12月的多组学数据,基于H3K27ac、BRD4、p300、Med1及新增的H3K4me1等5种标志物,在14个物种的543种细胞/组织中系统鉴定了496,071个SE和29,584,078个增强子。该平台提供了全面的基因组注释、功能富集分析、基于香农熵的SE特异性鉴定、交互式调控网络构建以及利用12种癌症scRNA-seq数据的肿瘤特异性SE探测工具。SEA 4.0通过标准化流程显著提升了数据质量和比较可靠性,为解码SE在发育和疾病中的机制提供了不可或缺的资源。

生物通 版权所有





