编辑推荐:
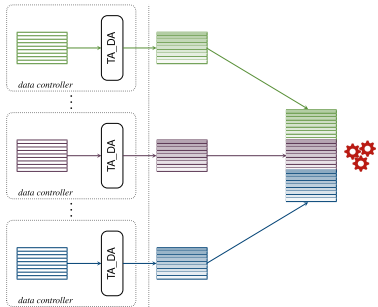
本文针对数据共享与隐私保护的矛盾,提出了一种目标感知的数据匿名化方法TA_DA。该方法在传统匿名化(提供k-匿名性和l-多样性保证)之前,根据下游数据分析任务(分类或聚类)对数据进行分组,从而在保护隐私的同时,最大限度地保留了数据对特定机器学习任务的效用。实验结果表明,TA_DA能有效减轻匿名化对分类和聚类性能的负面影响,为多数据控制方场景下的安全数据共享与分析提供了新思路。
(k, ℓ)-合规的,即每个叶节点代表的元组数量至少为k,并且包含至少ℓ个不同的敏感属性值。(k, ℓ)-合规的,即包含至少k个元组和至少ℓ个不同的敏感属性值。(k, ℓ)-匿名性,它们并集后的整个数据集自然也满足(k, ℓ)-匿名性。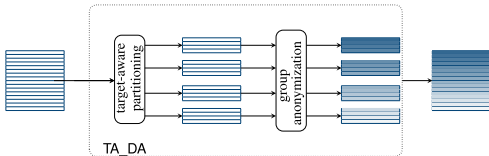
(k, ℓ)-合规决策树进行目标感知分区;2) 针对聚类任务,采用约束K-means算法(确保最小簇大小为k)并进行后处理合并以保证(k, ℓ)-合规性,完成目标感知分区;3) 对每个分区独立应用经过扩展以支持ℓ-多样性的Mondrian多维匿名化算法,实现组内匿名化。实验数据来源于公开的真实数据集(Bank, Nursery, Customer_segmentation),并模拟了多数据控制方场景。生物通 版权所有





