编辑推荐:
本研究针对乳腺肿瘤诊断与治疗中的临床挑战,探索了GPT-4o、DeepSeek-R1和DeepSeek-V3三种大型语言模型(LLMs)在肿瘤分类(AUC=0.848)、疾病解读(最高评分4.73±0.46)和治疗推荐(最高评分4.70±0.51)方面的性能差异。结果表明GPT-4o在分类任务中表现最优,而DeepSeek-R1在临床解释性方面更具优势,为AI辅助乳腺肿瘤诊疗提供了实证依据。
乳腺肿瘤作为全球女性最常见的恶性肿瘤之一,其诊断和治疗始终面临巨大挑战。临床实践中,医生常常需要面对模糊的影像学表现、非特异性的临床症状以及复杂的治疗策略选择难题。特别是在基层医院或资源匮乏地区,缺乏经验的医生更容易出现误诊或治疗不当的情况。随着人工智能(AI)技术的快速发展,大型语言模型(LLMs)展现出了强大的自然语言处理和知识提取能力,为改善这一现状带来了新的希望。
这项发表在《Scientific Reports》上的研究,由中国台州肿瘤医院的多学科团队合作完成。研究人员收集了2024年1月至4月期间45例乳腺肿瘤患者的完整临床资料,通过系统比较GPT-4o、DeepSeek-R1和DeepSeek-V3三种先进LLMs在肿瘤分类、疾病解读和治疗推荐三个关键任务上的表现,为AI在乳腺肿瘤临床决策支持中的应用提供了重要证据。
研究采用了多角度的评估方法:通过受试者工作特征(ROC)曲线和曲线下面积(AUC)客观评价模型的分类性能;由三位经验丰富的乳腺外科医生采用5分制Likert量表对模型的疾病解读和治疗推荐进行主观评分;同时分析了不同模型在良恶性病例中的表现差异以及预测准确性对主观评分的影响。
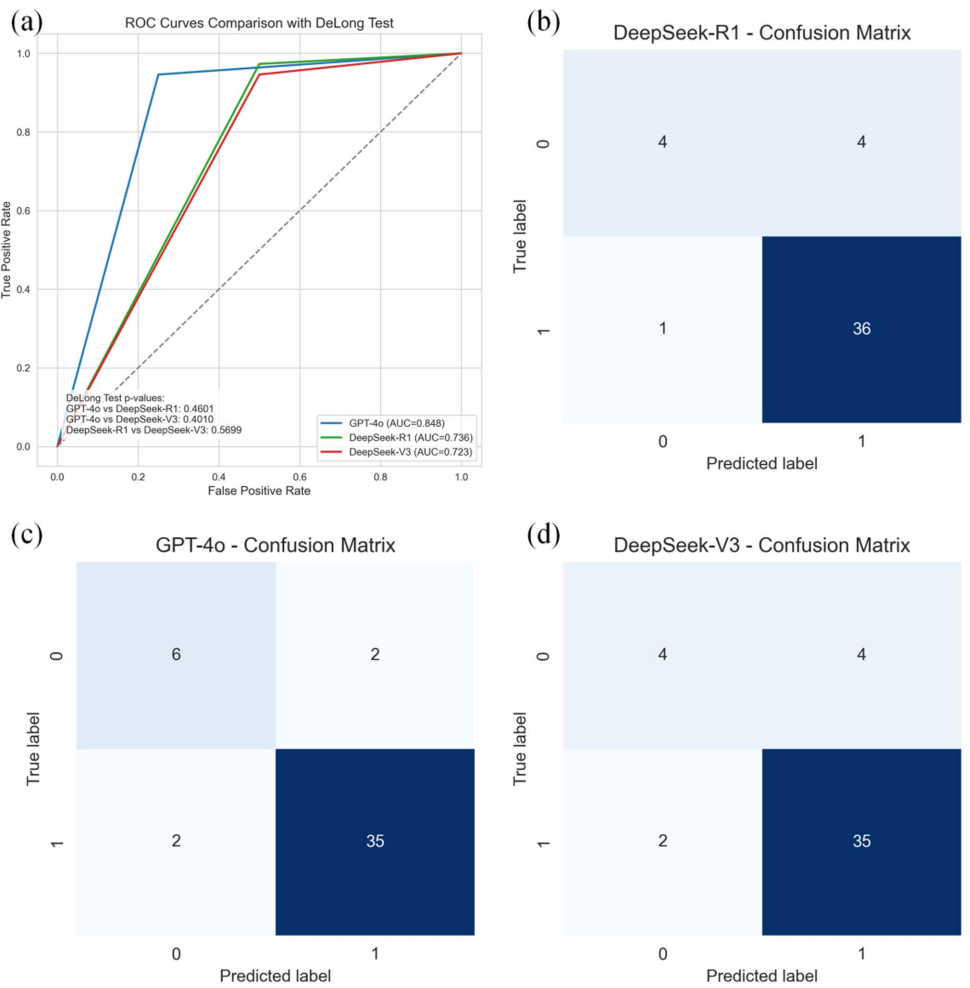
在肿瘤分类性能方面,GPT-4o表现最为突出,AUC达到0.848,准确率为91.1%,敏感性和特异性分别为75.0%和94.6%。相比之下,DeepSeek-R1和DeepSeek-V3的AUC分别为0.736和0.723,且对恶性肿瘤的识别敏感性均只有50%。虽然DeLong检验显示模型间AUC差异无统计学意义,但GPT-4o展现出更好的综合判别能力。
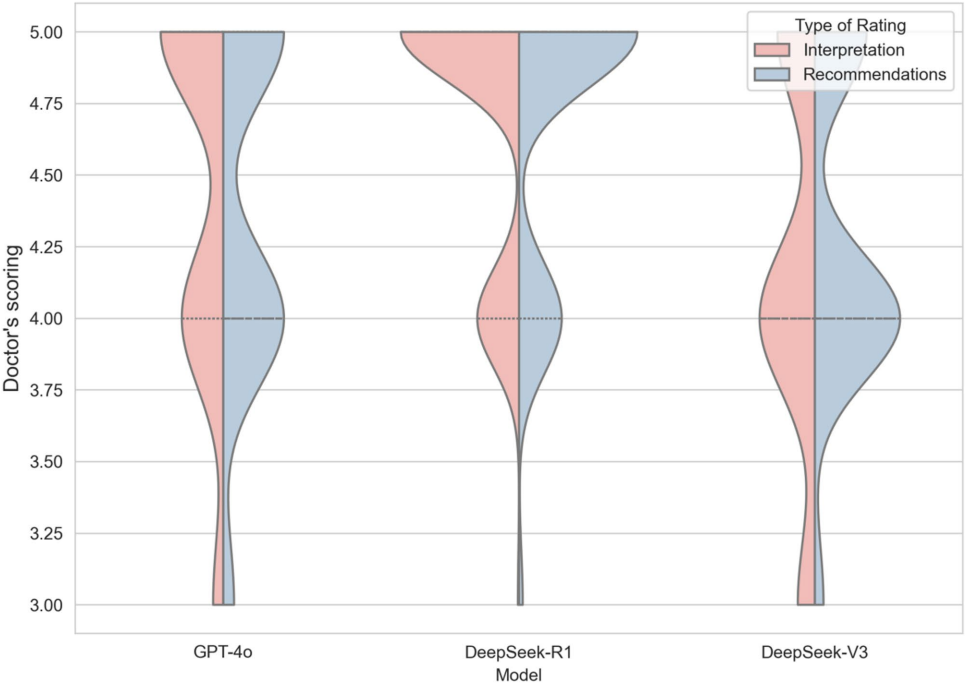
在临床实用性评估中,DeepSeek-R1获得了医生们的高度认可,其疾病解读平均得分为4.73±0.46,治疗推荐得分为4.70±0.51,均显著高于其他两个模型。值得注意的是,DeepSeek-R1的输出表现出极佳的稳定性,在医生间评分一致性方面明显优于GPT-4o和DeepSeek-V3。
研究还发现,所有模型在处理良性病例时的表现普遍优于恶性病例。特别是在治疗推荐方面,三种模型对恶性病例的评分都出现了明显下降,反映出LLMs在处理复杂恶性肿瘤时的局限性。然而,DeepSeek-R1在恶性病例的疾病解读中仍能保持较高水平(4.83分),显示出其在复杂临床场景中的潜在优势。
这项研究的重要意义在于首次系统评估了不同LLMs在乳腺肿瘤全流程管理中的应用价值。研究发现GPT-4o和DeepSeek-R1各有所长:前者在客观分类任务中表现更优,后者则在临床解释性和输出稳定性方面更具优势。这种互补性提示未来可以探索模型融合策略,以充分发挥不同架构LLMs的协同效应。
研究的局限性包括样本量较小、单中心数据以及缺乏多模态信息整合等。未来的研究需要扩大样本规模,纳入更多样化的临床场景,并探索如何将LLMs与影像学、基因组学等数据相结合,以进一步提升AI辅助诊断的准确性和临床实用性。尽管如此,这项研究为LLMs在乳腺肿瘤诊疗中的应用迈出了重要一步,为后续研究和临床实践提供了有价值的参考。
生物通 版权所有





