编辑推荐:
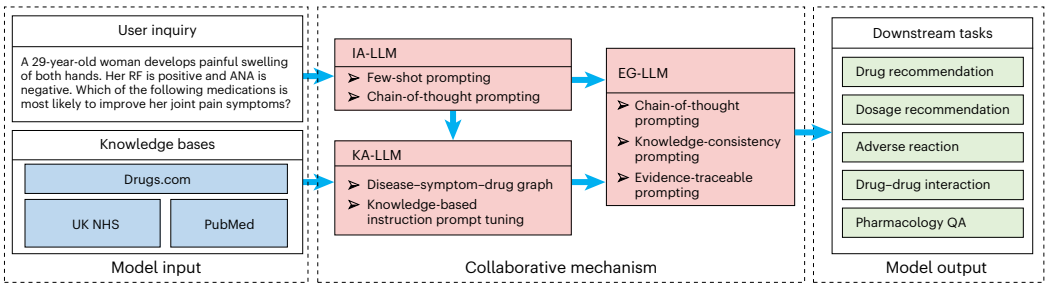
本研究针对大语言模型(LLM)在医疗领域应用中存在的幻觉问题与证据不可追溯性挑战,开发了知识驱动的协作式大语言模型DrugGPT。通过整合三大权威药物知识库(Drugs.com、NHS、PubMed)并构建疾病-症状-药物图谱(DSDG),引入协同机制(IA-LLM、KA-LLM、EG-LLM)实现自适应查询分析、知识获取与证据生成。在11个下游数据集测试表明,DrugGPT在药物推荐、剂量建议、不良反应识别、药物相互作用及药理学问答任务中均达到最先进性能,参数量仅为通用LLM的1/5,且在人类专家评估中展现优异的事实性、完整性与安全性。
随着ChatGPT等大语言模型在自然语言处理领域取得突破性进展,医疗领域也开始探索其临床辅助决策潜力。然而,这些模型在医疗场景中面临两大核心挑战:一是容易产生"幻觉"——生成看似合理但事实错误的医疗内容;二是缺乏证据可追溯性——无法提供建议的知识来源供临床医生验证。这些问题在风湿性关节炎治疗案例中尤为明显:当患者询问"最可能改善关节疼痛症状的药物"时,ChatGPT和GPT-4不仅错误推荐了甲氨蝶呤,还提供了缺乏事实依据的解释,声称"所有选项都用于类风湿关节炎治疗",而实际上D-青霉胺并不常用,甲氨蝶呤主要用于延缓疾病进展而非即时止痛。
为解决这一关键问题,牛津大学研究团队在《Nature Biomedical Engineering》发表了题为"A collaborative large language model for drug analysis"的研究,开发了专门针对药物分析的协作式大语言模型DrugGPT。该研究整合了Drugs.com、英国国家医疗服务体系(NHS)和PubMed三大权威知识库,构建了疾病-症状-药物图谱(DSDG),通过创新的协同机制实现准确的、基于证据的药物推荐。
研究采用模块化架构设计,主要技术方法包括:1)基于1750亿参数InstructGPT构建查询分析模块(IA-LLM),采用思维链(CoT)和少样本提示策略;2)知识获取模块(KA-LLM)利用MiniLM编码器构建DSDG图谱,实现药物-疾病-症状关系建模;3)证据生成模块(EG-LLM)采用知识一致性提示和证据可追溯提示策略。实验使用11个数据集(包括MedQA-USMLE、MedMCQA等公开数据集和新建的DrugBank-QA、MIMIC-DrugQA、COVID-Moderna三个防数据泄露数据集),采用随机抽样平衡测试集设计,所有分析均基于真实临床环境下的去标识化数据。
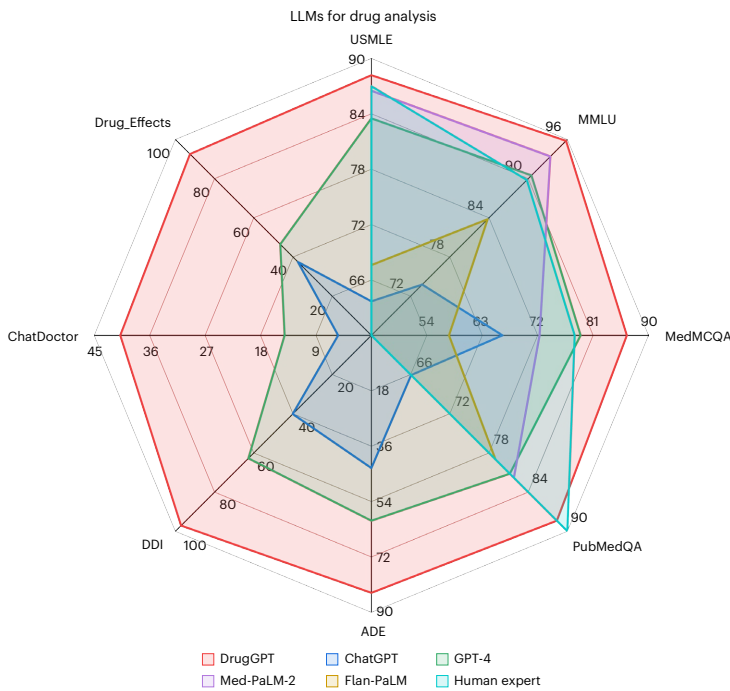
性能比较结果显示,DrugGPT在所有11个数据集上均达到最先进水平。在专业医学考试USMLE相关问题上,DrugGPT准确率达88.2%,显著超过ChatGPT(63.7%)和GPT-4(83.5%),且参数量仅为后者的1/5。在药物不良反应(ADE-Corpus-v2)和药物相互作用(DDI-Corpus)任务中,DrugGPT分别达到83.7%和97.1%的准确率,相比现有方法绝对提升17.3%和29.0%。特别是在需要列出所有适用药物的ChatDoctor数据集上,DrugGPT的F1值达到40.8%,表明其能提供更准确、更全面的药物推荐。
人类专家评估结果表明,DrugGPT在事实性、完整性、安全性和用户偏好四个方面均显著优于基线模型。两位医学专家对100份出院指导生成任务进行盲法评估,发现DrugGPT在76%的案例中被优先选择,在事实性(60%胜出)和安全性(69%胜出)方面表现尤为突出。这表明基于临床标准知识库的方法能够提供更可靠、更准确的循证推荐。
鲁棒性分析显示,即使仅使用10%的知识库,DrugGPT在药物效应和药物相互作用任务上的表现仍与GPT-4相当。随着知识库使用比例的增加,DrugGPT性能持续提升,在使用完整知识库时全面超越GPT-4。这一发现证明了该方法在知识库有限的应用场景中仍能保持良好性能,并显示出在其他医学领域(如诊断和预后)的应用潜力。
推理能力测试在零样本学习设置下进行,DrugGPT在所有任务和数据集上均取得最佳结果,在某些数据集(如DDI、Drug-Effects和ADE)上准确率比GPT-4和ChatGPT高出约40%。值得注意的是,尽管DrugGPT专为药物查询设计,但其在通用医学问答(如USMLE、MedMCQA和PubMedQA)上的表现也超越了专门医学LLM Med-PaLM-2,且参数量减少1.8倍。
泛化性能研究通过构建DrugQA数据集评估模型对未见药物类型的泛化能力。采用跨类别/跨类型/跨作用机制(MoA)预测设置,测试模型在训练时未见过的药物类别上的表现。结果显示,即使在这种强泛化要求下,DrugGPT在大多数情况下仍优于之前的GPT-4基线模型,在"酸类"、"小分子"和"抑制剂"分类上的准确率分别达到88.9%、88.4%和89.5%,表明其能够很好地泛化到与训练药物相似度较低的新药物。
讨论分析表明,当引入新知识时,DrugGPT在原有知识上的性能仅有轻微下降(准确率降低0.4-1.5%),说明灾难性遗忘的影响有限。研究还验证了持续学习的作用,在不同版本的GPT-4模型(GPT-4-0613、GPT-4-1106和GPT-4-0125)上应用DrugGPT方法,性能均获得一致提升。协同机制中各组件(IA-LLM、KA-LLM和EG-LLM)均带来显著改进,其中知识获取模块贡献最大,将USMLE数据集上的性能从55.8%提升至82.7%。
案例分析显示,DrugGPT能够正确分析输入查询中的药物和症状,准确捕捉相关知识,并提供证据支持。例如,在风湿性关节炎案例中,模型基于"非甾体抗炎药通常用于即时止痛"的知识,正确推荐NSAIDs作为改善关节疼痛症状的最佳选择,同时提供准确的解释和证据来源。
研究结论表明,DrugGPT通过整合权威知识库和协同机制,有效解决了LLM在医疗领域中的幻觉和证据不可追溯性问题。该方法在多个药物分析任务中表现出色,参数量远少于通用LLM,且具有很好的泛化能力和鲁棒性。研究提供的解决方案不仅适用于药物查询,还有潜力应用于其他医学领域,提高AI聊天机器人在下游任务中的性能,为临床决策提供更准确、更可靠的支持。
这项研究的重要意义在于首次系统性地解决了LLM在医疗领域应用的核心痛点,建立了知识驱动、证据可追溯的药物分析新范式,为LLM在临床环境中的安全可靠应用提供了重要技术保障。
生物通 版权所有





